
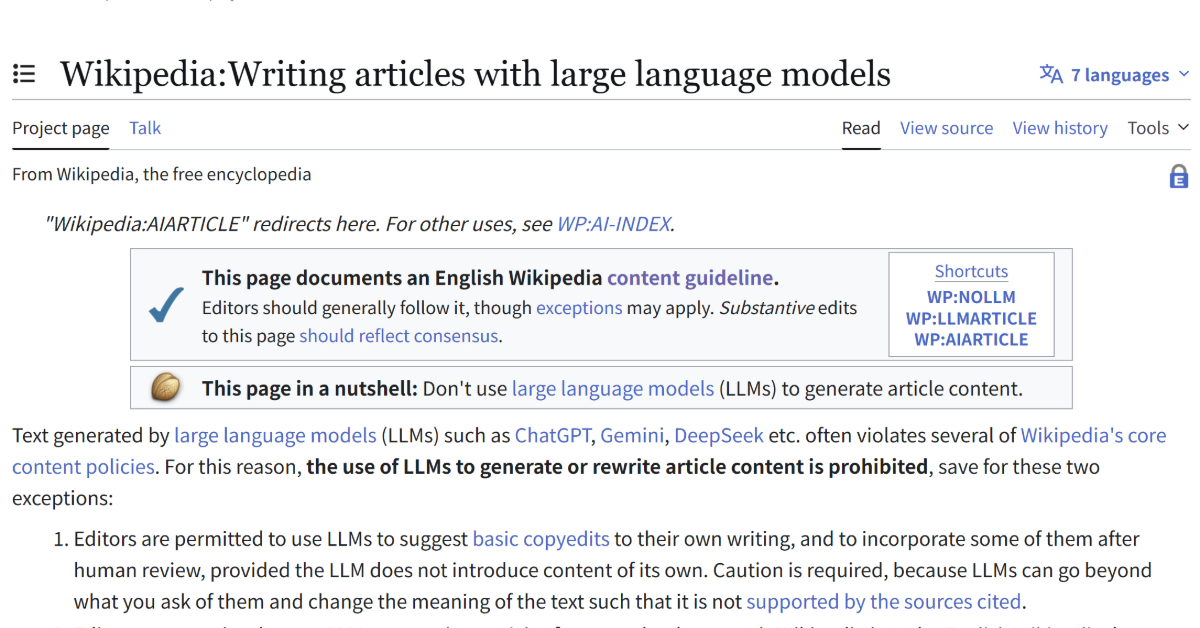
Wikipediaは、最近オープンな議論を経て、LLM(大規模言語モデル)による記事生成を原則禁止する方針を決定しました。この動きには、様々な背景があるんですよね。特に、信頼性や著作権に関する懸念が強く影響しています。Wikipediaは、誰でも編集できるプラットフォームであるため、情報の正確性を保つことが重要です。しかし、AIが生成するコンテンツがその基準を満たすかどうか、疑問が多く残ります。
Wikipediaの記事生成に関する現状
Wikipediaは、誰でも参加できるオンライン百科事典として知られています。ユーザーが自ら記事を編集し、情報を追加するスタイルは、多くの知識共有を可能にしました。しかし、AIの進化に伴い、自動生成されたコンテンツが増える中で、記事の信頼性が脅かされるという新たな課題が浮上しています。
LLMが引き起こす懸念とは?
LLMを用いた記事生成には、いくつかのリスクが存在します。特に重要なのは、情報の正確性と著作権の問題です。例えば、ある企業の製品情報を自動生成した場合、その情報が正確である保証はありません。さらに、LLMが他の著作物から情報を引き出している場合、無断転載とみなされる可能性も出てきます。
もしAI記事生成が許可されるなら、どうなる?
仮にWikipediaがLLMによる記事生成を許可した場合、情報の質が著しく低下する可能性があります。もちろん、AIは多くの情報を瞬時にまとめる能力がありますが、その内容が正確かどうかは別問題です。情報の信頼性が損なわれると、ユーザーがWikipediaにアクセスする意味が薄れてしまうかもしれません。
現場でどう活用するか
このニュースを受けて、現場でどのように活用すれば良いのか、考えてみる必要があります。例えば、情報を収集する際には、あくまで人間がチェックを行うことが肝心です。自動生成された記事を鵜呑みにせず、他の信頼できるソースと照らし合わせることが大切だと思います。
最近のWikipediaの方針変更には、多くの示唆があります。AIを利用することは便利ですが、その影響を理解し、どのように活用するかを考えることが重要です。次に確認すべきことは、信頼性の高い情報源を見極めるための基準を持つことです。
元記事のタイトルは「Wikipedia、LLMによる記事生成を原則禁止に」で、URLはこちらです。